生成式AI(人工智能)的引擎——大规模语言模型(LLM)正在接连问世。各公司竞相宣传其开发的LLM性能卓越,然而与英语相比,日语环境下用于客观评估AI性能的测试数据仍不够完备。早稻田大学的河原大辅教授(信息学)指出:“为了提高性能,建立日语的评估机制不可或缺。”

河原大辅教授。1999年毕业于京都大学研究生院。曾任信息通信研究机构和京都大学副教授等职,2020年任早稻田大学基干理工学部教授。专业为自然语言处理和智能信息学。
——评估AI性能的方法都有哪些?
“关于文本的AI性能评估,主流方法是2018年在美国出现的‘GLUE’测试组。该测试组涵盖判断句子内容是否积极或消极,以及简单地询问文章题目和知识问题等。我的研究室也与雅虎公司合作,制作了日语版问题与回答的测试数据。”
“然而,随着生成式AI的发展,这些测试方式很快就过时了。如果用人类来比喻的话,这些测试面向小学生已经够用了,但是应试者却突然变成了大学生水平。所以新的测试方式在美国等地开始接连出现。”
“其中之一是被称为‘MT Bench’的多方面评估方法。代表题例包括摘要、编码、数学、逻辑问题、角色扮演等,其8个领域分别公开了精心设计的问题。许多问题的答案不仅限于一个。该方法已被广泛用作客观衡量英语LLM能力的指标。”
——在答案不唯一的情况下,由谁来评分?如何评分?
“若依靠人工逐个评估,既费时又费钱。目前普遍的做法是,让被视为‘最优秀LLM’的美国OpenAI公司的‘GPT-4’进行自动评分。已有研究成果表明,这样得到的结果与人工评估存在一定相关性,并且不会偏袒与GPT-4自身情况接近的答案。”
“然而,使用AI评估AI时也存在偏差问题。会出现无关文本内容,对字数较多或率先看到的答案给予高度评价——这些也是教师评分时也容易出现的问题。还有一些问题,AI仅仅通过学习公开的测试数据就能够提高正确率。”
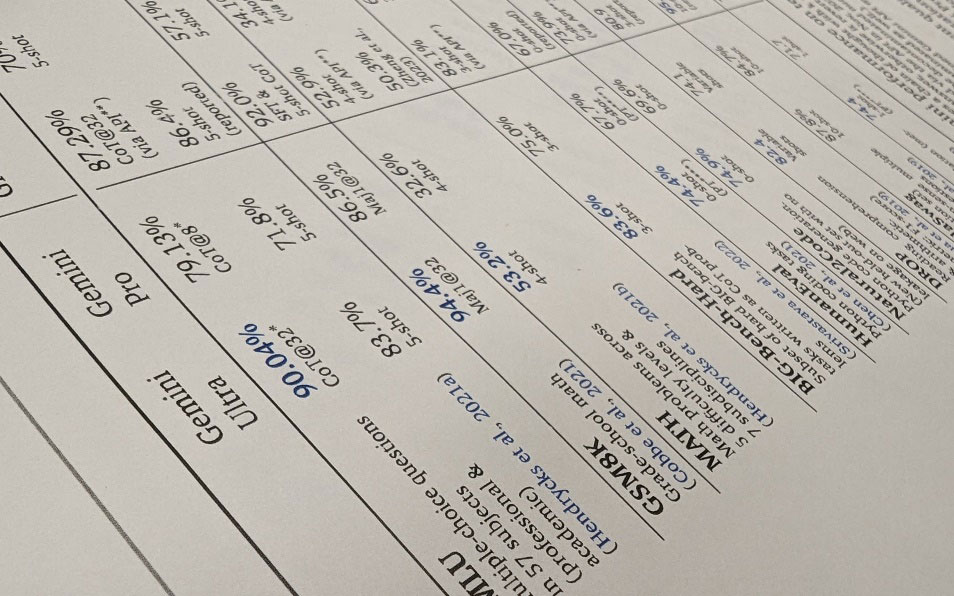
美国谷歌公司公开了高难度的多方位测试结果
——各类企业都在开发独特的LLM并宣传其优秀之处。
“美国谷歌和OpenAI等公司公布了比较多样的评估结果。然而,在日本国内企业中,有些评估案例被认为只展示了对自家公司有利的部分。”
“事实上,日语LLM的实力还远远不够。基于‘GLUE’等初级指标进行比较时,即使在日语测试中,OpenAI公司的GPT-4依然是最优秀的,而该公司的旧模型与日本企业的某些模型水平相当。如果使用更高级的测试指标,差距想必会进一步扩大。”
“与LLM的开发热潮相比,开发者制作日语评估数据的努力并不积极。尽管制作‘精心设计的问题与答案’的数据是一项持续而昂贵的工作,但它不仅对评估有用,对于生成式AI进行附加学习时也很重要。为了提高日语LLM的性能,数据的制作是不可或缺的。”
日文:伴正春、《日经产业新闻》、2024/2/26
中文:JST客观日本编辑部