日本国立研究开发法人产业技术综合研究所(以下简称“产综研”)全球首次开发出了利用由数学公式自动生成的大规模图像数据集来构建AI图像识别模型(预学习模型)的方法。这是通过NEDO(新能源产业技术综合开发机构)“与人类共同发展的新一代人工智能技术开发项目”获得的结果。产综研在6月19日至24日于美国新奥尔良举办的国际会议IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022上介绍了开发的具体内容。
这种方法不仅实现了与目前使用真实图像和经过人工判断的教师标签(为变成可以学习的形式,为图像附加的标签信息)相同或更高的图像识别精度,还解决了对AI识别图像数据进行商业使用时存在的课题,比如收集大量供AI学习使用的真实图像数据、确保图像数据的隐私,以及削减添加教师标签的成本等。该方法今后还有望应用于自动驾驶、医疗和物流等不同环境的AI构建。

图1:无需基于真实图像和人类判断的教师标签,而是通过由数学公式生成的教师标签学习的图像理解型AI概念图(供图:产综研)
目前各个领域都在陆续引进AI,但制造和医疗现场等领域存在无法收集AI学习所需的大量数据的情况,以及为此需要付出高成本的情况,这成为引进AI技术的障碍。
因此,作为克服这一障碍的手段之一,利用AI通过大量各种真实图像数据预先学习的图像识别模型(预学习模型)的方法取得了进展。然而,学习图像在数据透明性方面存在一些问题,比如侵犯隐私,或者不当添加的教师标签输出不公平的识别结果等,这成为了商业用途所面临的课题。
因此,开发能在解决隐私侵犯和不公平的识别结果等图像数据相关问题的同时,实现与原来相同或更高的识别精度的预学习模型,成为AI领域亟需解决的课题。
产综研此次开发的方法在预先学习中完全不使用真实图像,通过用数学公式(生成图像模式和教师标签的生成规则)自动生成图像模式和教师标签,可以削减添加标签的成本,无需担心真实图像的数据数量、伦理问题和权利关系,能放心构建AI图像识别模型(预学习模型)。

图2:生成预学习模型使用的图像示例。
图上部是以前使用的标准真实图像,中间和下部是此次提出的利用数学公式(分形几何/轮廓形状)生成的图像。(供图:产综研)
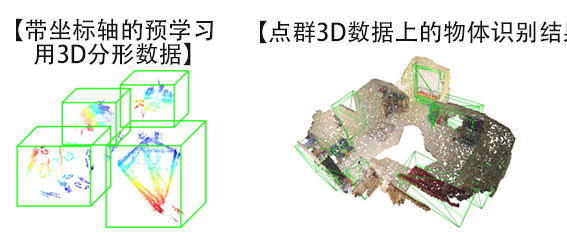
图3:用于3D空间物体检测的扩展数据集(供图:产综研)
另外,产综研利用通过新方法构建的预学习模型识别了用于图像识别性能测试的ImageNet的图像数据集,确认比学习基于真实图像和人工判断的教师标签的现行方法精度更高,达到了实用水平。

图4:未来展望(供图:产综研)
该数据集及预学习模型已从6月13日开始在官网主页(Formula-driven Supervised Learning)公开。
通过公开利用新方法构建的预学习模型,使用者可以从具有一定精度的图像理解AI开始各自的开发。
原文:《科学新闻》
翻译编辑:JST客观日本编辑部
【论文信息】
会议:IEEE/CVF International Conference on Computer Vision and Pattern Recognition(CVPR)2022
论文1:Replacing Labeled Real-image Datasets with Auto-generated Contours
论文2:Point Cloud Pre-training with Natural 3D Structures