计算能力掌握着AI竞争的未来。科学家们正在研究如何让超级计算机学习海量数据开发人工智能(AI),以实现作为新药开发、材料开发和自动驾驶汽车等的划时代技术。日本理化学研究所(以下简称“理研”)计划利用全球最强的超级计算机“富岳”的全部计算能力实现技术创新,类似的动向在欧美也日益明显。

理化学研究所的超级计算机“富岳”(图片由理研提供)
理研预定2022年度利用富岳的全部计算能力开发全球最大的AI系统。富岳拥有16万个CPU(中央处理器),用于AI的话,每秒可进行约2Exa(1Exa为100京)次的计算。理研计划利用全部的CPU,在新药开发、材料开发和自动驾驶等各领域实现划时代的AI系统。
AI开发一般先将不同目的(比如新药开发或自动驾驶等)的数据大量输入计算机让超级计算机学习。但有时即使增加数据量,性能也无法提高,或者依然会做出错误的判断。近年来针对学习方法的研究取得了进展,机器翻译等领域已经可以通过增加数据量和计算量来提高性能。
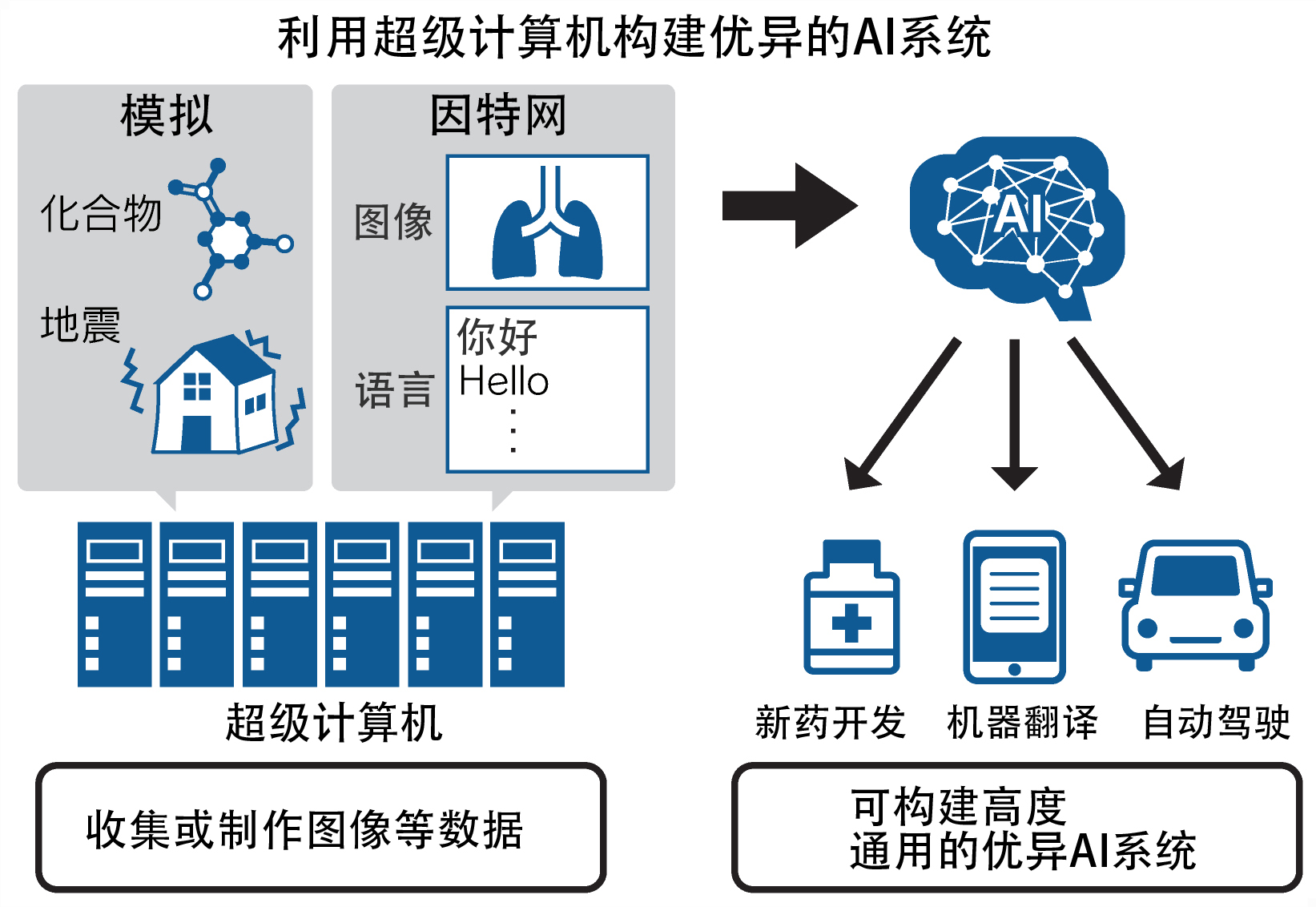
目前,研究的重点集中在超级计算机的计算能力、需要学习的数据量和影响计算结果的“参数”数量上。比如医院的诊断用AI,其数据就包括性别、年龄和病史等项目。
之所以使用超级计算机,是因为需要学习大量数据。以汽车自动驾驶为例,据说一辆汽车行驶一年通过摄像头和光传感器能收集到约2PB(1P为1000万亿)的数据。
理研计算科学研究中心主任松冈聪表示:“新药开发、自动驾驶和机器翻译等领域普遍要处理PB级以上的数据。要想利用如此大量的数据构建AI,必须有优异的超级计算机。”
理研的目标是开发划时代的AI系统。美国微软公司投资的研究企业Open AI于2020年6月公开的AI“GPT-3”能写出接近人类水平的自然流畅的文章,并由此掀起了创新热潮。GPT-3利用能处理1750亿个参数的大规模计算模型提高了性能。
富岳目前的计算能力位居世界第一,它可以在5120TB(1T为1万亿)的数据上运行训练过的AI,这比GPT-3用于训练的数据多出约114倍。预计参数的数量也在同等水平以上。
松冈介绍说:“可以大量生成图像和化合物的结构数据,让AI高速记忆。只有拥有利用超级计算机构建的AI,才能进行划时代的新药研究等。”目前的主流方法是,让AI自己生成不足的数据并有效地进行学习。
理研还将利用富岳详细分析与疾病有关的体内蛋白质的结构,探索药物的候选物质。目标是利用计算机断层扫描装置(CT)等的医疗图像实现癌症的早期诊断。此外,还将大力开发预计将在2030年代实现的“L5”级别的汽车全自动驾驶AI系统。
利用超级计算机构建AI的主要举措 |
|
研究主体 |
内容 |
理化学研究所(日本) |
利用“富岳”试制全球最大的AI。为在超早期发现癌症和实现全自动驾驶开辟道路。 |
微软(美国) |
与Open AI公司共同构建AI专用超级计算机。 |
英伟达(美国) |
拥有排名跻身全球前十的超级计算机,用于构建AI。 |
CINECA(意大利) |
正在构建全球最快的AI超级计算机“Leonardo”。 |
百度(中国) |
正在研究语音辨识和图像识别及自动驾驶等 |
利用超级计算机开发AI的研究是美国谷歌和斯坦福大学于2011年开始推进的。目前中美处于领先地位,相关企业也引人瞩目。“美国英伟达和微软拥有位列全球前十的超级计算机。中国百度也在开发之中”(松冈)。
欧洲方面,意大利约100所大学和公共机构组成的研究者组织“CINECA”正在构建全球最快的AI用超级计算机“Leonardo”,拥有每秒10Exa次的计算能力,预定2022年投入使用。CINECA的负责人Sanzio Bassini表示:“将用来研究利用现有药物治疗新冠病毒感染症以及预测暴雨和地震等”。
AI备受期待。美国Alphabet公司旗下的英国DeepMind公司2020年11月开发出一款AI,解决了已存在半个世纪的生物学难题。该AI在短时间内预测出了有助于进行新药开发的蛋白质的立体结构。
预计今后各国及各企业的竞争还会继续。据Open AI公司估算,构建AI所需的计算能力约3个半月就会翻一番。日本产业技术综合研究所(以下简称“产综研”)人工智能云研究团队的组长小川宏高表示:“利用超级计算机开发AI的竞争今后也会越来越激烈。”
要想取胜,需要向超级计算机投资并培养人才。产综研等正通过举办讲习会的方式致力于人才培养。小川组长表示,“日本国内企业很少有向超级计算机投资的”。如果错过了构建大规模AI的浪潮,日本的产业竞争力可能会被进一步削弱。
日文:草盐拓郎、《日本经济新闻》,2021年4月5日
中文:JST客观日本编辑部